I want to change how we — as a community — approach, analyze, and understand performance problems. Often I see questions like "What's the best way to do X?", "What is the fastest library to do Y?". Superlatives are human nature, it seems. But for performance work, they can be counter-productive.
Performance on the web can be a problem. Developers will always try to push the boundaries of what they can get away with and that's a good thing. I don't want to change that.
Apply snake oil generously to affected area.
aka "Rules Not Tools". I saw "snake oil" used in a tweet by Alex Russell and I think it perfectly captures both the opaqueness and the unreliability of the treatment.
Examples:
- An animation is janky. Set
will-change: transformon the animated element. - Don't use forEach(), for loops are faster.
- Use bundling to make your site load faster.
- Don't use the
*selector. It is slow.
All of these are true in a specific context. The thing to realize is that slowness or a janky animation is a symptom, not an illness. What is needed here is a differential diagnosis procedure. A janky animation can have any number of causes, but it's likely that only one is present. For example, if the jankiness is caused by garbage collection of big chunks of data every frame, will-change: transform will do you no good. If anything, it will increase the memory pressure and might make things even worse.
I don't remember who said it, but the phrase "If you didn't measure it, it's not slow" really stuck with me. However, focusing on just measuring can lead to Microbenchmark Frenzy™️.
Note: For the rest of the blog post I'm going to talk about speed optimizations. But all of this also applies to other optimizations like reducing memory footprint.
Microbenchmarks
Recently I have noticed a lot of attention being given to microbenchmarking. In microbenchmarking, you try to decide between two competing techniques by running them a couple thousand times in isolation to see which one is faster. You stick with the technique with the better numbers.
Please don't get me wrong, microbenchmarks have a place. I do them. Many others do, too. They are a valuable tool, especially with frameworks like BenchmarkJS that make sure your numbers are statistically significant. But benchmark frameworks can't help you make sure that your benchmark is actually meaningful. If you don't know what you are testing, the results can lead you astray. For example, in my blog post on deep-cloning I was benchmarking the performance of const copyOfX = JSON.parse(JSON.stringify(x)). It turns out that V8 has a cache for object mutations. The fact that I reused the same x value across tests skewed my numbers. I was testing a cache more than anything else. If it wasn't for Mathias reading my article, I would have never known.
Trade-offs
So let's assume you have either written or found a significant and meaningful microbenchmark. It shows you that you should rather do Technique A instead of Technique B. It is important to realize switching from B to A will not just make your code run faster. Almost every performance optimization is a trade-off between speed and something else. In most cases, you give up readability, expressiveness and/or idiomaticism. These meta-values won't show up in your measurements, but that doesn't mean that they can be ignored. Code should be written for humans (including your future self), not the computer.
This is where I see microbenchmarks getting abused. Just because there is a way to make a certain operation faster, doesn't mean it's worth taking the trade-off on expressiveness. People often only publish the numbers of their microbenchmark and others will think they have hard evidence that A is better than B and so you should always use A. This is how snake oil is made. Part of the problem is that it's hard to quantify expressiveness. How much faster does a piece of code have to get to make up for the loss in readability? 10%? 20%?
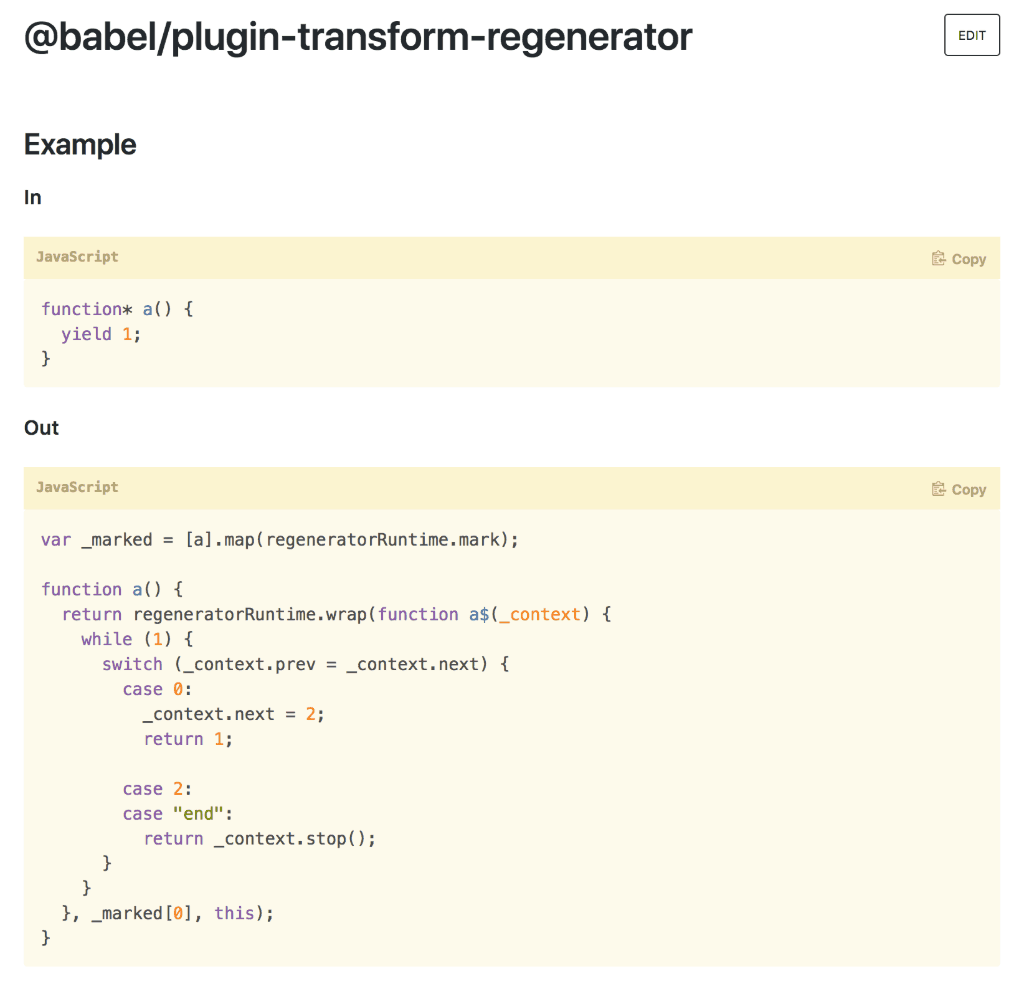
There is an argument to be made for static analysis and transpilers. You get to write readable and idiomatic code but can ship less readable but more performant code to production. Something like @babel/present-env allows you to write modern, idiomatic JavaScript without having to worry about browser support and performance implications. The trade-off here is the cost in file size and inscrutability of the output. Some features can only be transpiled with a significant increase in code size which impacts download and parsing time. One of the more extreme examples is the way generators are transpiled. You need to load a generator runtime object as well as making your generator function significantly larger. Again: This doesn't mean that you shouldn't use generators or not transpile them. But you need to be aware of this trade-off to be able to make an informed decision. It's trade-offs all the way down.
Budgets
This is where budgets can help. It is important to set yourself budgets for various aspects of your project. For web apps one popular choice are the RAIL guidelines. If you are aiming to run your web app at 60fps, you have 16ms per frame. To make an UI feel responsive, you have about 100ms to visually react to a user interaction. Once you have budgets, you profile your app and see if you can stay within these budgets. If not, you now know where to spend your optimization efforts.
Budgets also contextualize costs. Let's say I have a button on my UI that, when clicked, causes a fetch() of the most recent stock data and puts it on the screen for the user to read. With a network round-trip, data processing and rerendering the time it takes from the user clicking to a visual update takes 60ms. This is well within the RAIL guidelines mentioned above. We actually have 40ms left over! If you are considering to move that data processing logic to a worker, you add an additional delay because of the cross-thread communication that has to happen between the main-thread and the worker. In my experience, that additional delay is usually around 1 frame (16ms), giving us a total of 76ms.
If you were to make the decision with a microbenchmarking mindest — by just looking at the numbers without context — workers will seem like a bad idea. However, the question ought not to be "what is faster?" but rather "what is the trade-off?" or "can I afford this given my budget?" In the worker example we pay 16ms, something we can easily fit into our 40ms of left-over RAIL budget. What we get in return depends a bit on your perspective, but in this example I want to focus on resilience. If the server sends an unexpectedly massive JSON response for the stock data, decoding could take a considerable amount of time and block the main thread. If the decoding and processing happens in a worker, none of this would affect the main thread and keep your app responsive.

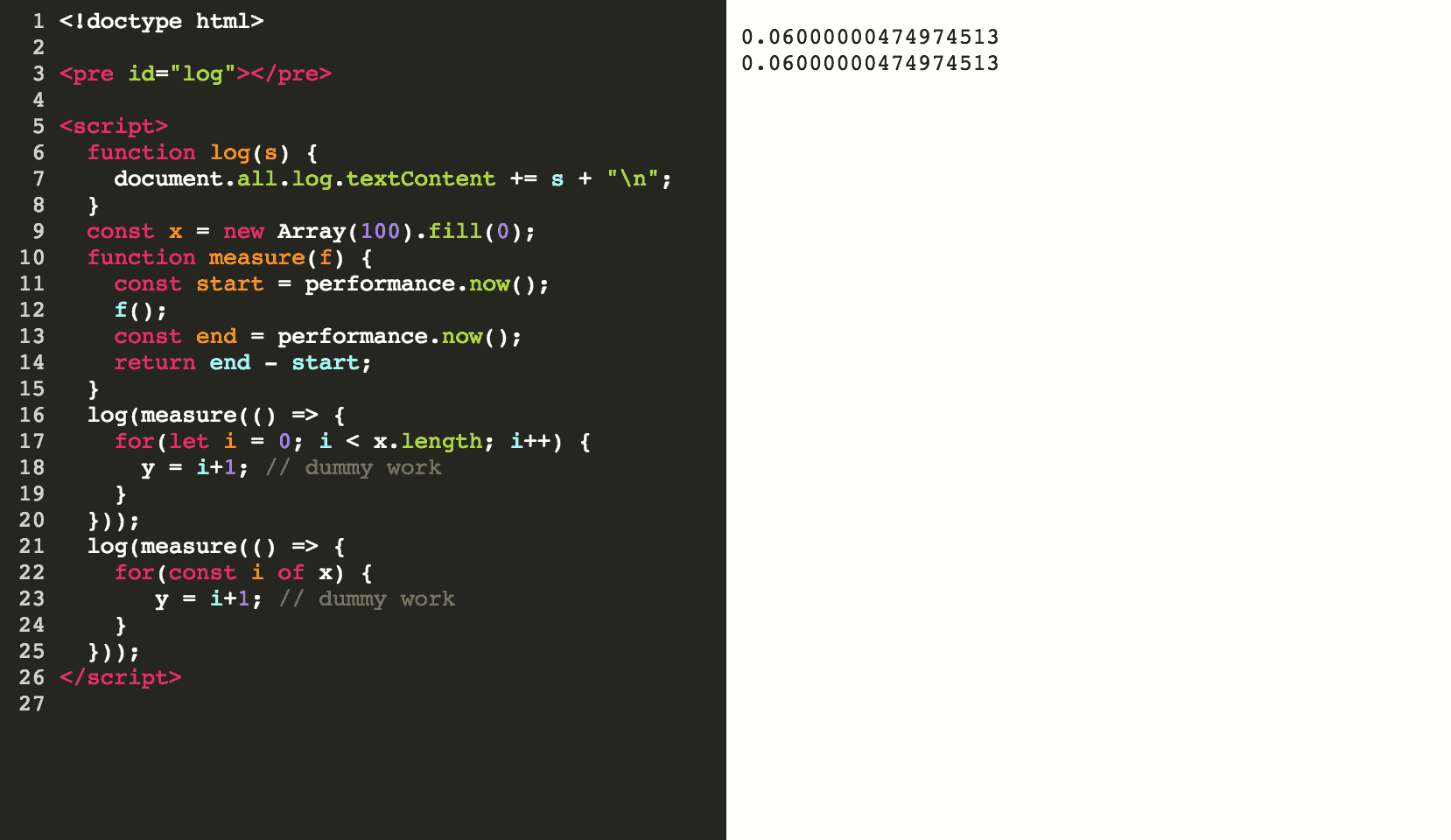
Another example: Until about a year ago, using a for-of-loop to iterate over an array was 17x slower than using a normal for-loop (Note: six-bench was run in April 2017. Lots of things have changed since then in v8 and babel). I still see people avoiding for-of loops because of this finding.
Let's look at concrete numbers: I iterated over an array with 100 elements in Chrome 55 (released in December 2016, before six-speed was run). Once with a for-of and once with a normal for-loop:
- for-of-loop: 134µs
- vanilla for-loop: 65µs
Clearly, the vanilla for-loop is faster (in Chrome 55), but the for-of loop gives you implicit boundary checks and makes the body of your loop more readable as you don't have to use index notation. Is that worth saving ~60µs? Well, it depends. Almost always the answer is no. If you were using for-of loops in a hot path (like code that runs every frame of a WebGL app), you might have a point. However, if you were just iterating over a couple dozen elements once the user clicks a button, I wouldn't bother thinking about performance. I always err on the side of readability. And for what it's worth, in today's Chrome 70, both loops are exactly the same speed. Thanks, V8 team!
It depends (on the context).
With all that said: There is no performance advice that is always good. Heck, there's barely any performance advice that is mostly good*. Technical requirements, target audiences, target devices and company priorities just differ too much from case to case. It depends. If you want my advice, here's how I try to do tackle optimizations:
- Set yourself a budget.
- Measure.
- Optimize the parts that are blowing your budget.
- Make a decision with context.