Range requests allow a <video> tag to seek through a video file. Adding support to your dev server is a fun challenge and taught me some interesting things about WHATWG Streams.
I’m working on my backup server and want to use Perkeep as one of my main data stores. I am going to write about my backup server and Perkeep some other time, but for now it’s enough to know that Perkeep is a file storage system (kinda) and that their default web UI is somewhat clunky. This made me wanto write something myself. I looked up what APIs the server exposes and how my frontend could display the files stored in Perkeep.
Perkeep
Perkeep stores your data as chunk of bytes called blobs. Each blob is content-addressable, meaning that each blob is identified by its SHA224 hash. And everything is a blob. Most data will be opaque binary data. But if upon upload the server can interpret the blob’s content as JSON and finds a camliVersion and a camliType property on that JSON object, the server will do some advanced processing. For example, if you upload a file, the CLI will break the file’s contents into multiple chunks, upload each chunk, and then upload another blob that ties all these chunks together. That blob looks something like this:
{
"camliVersion": 1,
"camliType": "file",
"fileName": "my_diary.txt",
"parts": [
{
"blobRef": "sha224-a3a58c8a25f7206342bc1b5b0b5e542f97e2c6a467194aa5c37dc80d",
"size": 32451
},
{
"blobRef": "sha224-7c4ba3bb272a5ce9d4f6f8d9106e0180f24e465d7b73e3788e030108",
"size": 421
}
]
}
Perkeep knows that if a blob corresponding to the file schema comes in, it has to add this blob to an bunch of indexes, allowing you to find that file quickly by searching by file name, file size or other attributes. As mentioned, a file’s contents are not stored as a single blob but broken up into multiple, smaller blobs that are linked together by the parts property. Perkeep uses a rolling checksum algorithm, similar to what rsync does, where a rolling window of bytes is used to decide whether the current byte is a chunk boundary. The parameters of this chunking algorithm are calibrated to make the average chunk size roughly 64KiB. The chunking has the advantage that the amount of data uploaded or stored is minimized if two files share a lot of content or the same file is re-uploaded after some minor modifications.
To download a file as a whole, you need to request each chunk and reassemble the file. I can do that in the browser, but things become a bit messy when you want to use the full file for an <img> tag or view the resulting PDF. As I was planning to write some CLI tools as well, I decided to add a special API endpoint in my Deno backend that serves the entire content of a file. Since the parts are listed in order, it also opens up the possibility of streaming the file contents without having to store the entire file in RAM first.
WHATWG Streams
I’m using Deno for the backend of my UI, which aims to implement the exact same APIs as the web platform. Therefore, WHATWG streams are available out of the box in Deno to achieve streaming. Deno also uses a ServiceWorker-inspired API to start a low-level HTTP server, and each request and response comes with a ReadableStream. However, as with many low-level APIs, using them puts a lot of the burden on the developer, specifically when it comes to efficient usage and error handling. Deno’s standard library comes with a std/http module that contains a serve function, that invokes a handler function for every request that comes in and expects a promise for a Response in return. Just like Response on the web, response.body is a ReadableStream<Uint8Array>:
import { serve } from "https://deno.land/std@0.118.0/http/server.ts";
import { serveFile } from "https://deno.land/std@0.118.0/http/file_server.ts";
import { join } from "https://deno.land/std@0.118.0/path/mod.ts";
I;
const STATIC_ROOT = new URL("./static", import.meta.url).pathname;
function handle(request: Request): Promise<Response> {
const parsedURL = new URL(request.url);
// Requests for `/raw/<some sha224 hash>`
if (parsedURL.pathname.startsWith("/raw/")) {
const ref = parsedURL.pathname.slice("/raw/".length);
return streamBlob(req, ref); // TODO!
} else {
return serveFile(request, join(STATIC_ROOT, parsedURL.pathname));
}
}
await serve(handle, { port: 8080 });
Most requests are handled by the standard library’s serveFile function, which I use to serve files from STATIC_ROOT on the local filesystem. If a resource from /raw/ is requested, our special logic kicks in, extracts the blob hash and calls streamBlob(). This is where it gets interesting:
// perkeep.ts is a class that wraps the JSON HTTP API of Perkeep.
import Perkeep from "./perkeep.ts";
const PERKEEP_URL = new URL(
Deno.env.get("PERKEEP_URL") ?? "http://localhost:3179"
);
const perkeep = new Perkeep(PERKEEP_URL);
async function streamBlob(req: Request, ref: string): Promise<Response> {
const { parts } = await perkeep.getJSONBlob(ref);
const { readable, writable } = new TransformStream();
(async () => {
// Stream each part
for (const part of parts) {
const resp = await fetch(perkeep.blobURL(part.blobRef));
await resp.body.pipeTo(writable, { preventClose: true });
}
// … and signal that we are finished afterwards.
await writable.close();
})();
return new Response(readable);
}
To concatenate all the individual parts into one, consecutive stream, we create a TransformStream. TransformStreams without a transform function will forward everything that is written into their writable to their readable, without any transformation in between. The readable will be our Response’s body. In a concurrent async IIFE, we fetch each part’s contents using fetch(), grab the ReadableStream<Uint8Array> body and feed them into our writable using pipeTo, which will cause all chunks to come out the readadable in order. We just re-assembled the file on the fly!
In the case of using the output of one stream as the input to another, there are three scenarios that we need to think about:
- The entire input stream was forwarded successfully
- The input stream encounters an error
- The output stream encounters an error
Each of these events, by default, are forwarded with the approrpiate semantics. If the input stream is finished (scenario 1), the output stream is closed. If the input stream errors (scenario 2), the output stream is “aborted”. If the output stream errors (scenario 3), the input stream is “cancelled”. In our scenario, we want to propagate errors, as there’s no point in continuing concatenating parts if the source or the destination encountered some form of error. However, the response consists of multiple parts, so we don’t want to close the stream just because one part is finished. That’s what the preventClose: true option achieves. pipeTo also provides options to opt out of forwarding errors.
Note: For more details on “abort”, “cancel” and other terminology on WHATWG streams, I genuinely recommend looking at the WHATWG Streams spec.
And that’s how you concatenate multiple streams into one. pipeTo makes it fairly uncomplicated.
Error handling
One of the great features about WHATWG streams is their ability to communicate backpressure. That is they let the producer of data know at what rate the data is being consumed (take a look at the desiredSize property on the ReadableStreamDefaultController and WritableStreamDefaultWriter). fetch() uses this mechanism to detect when the internal buffer reaches a certain threshold (called the “high water mark” in the stream spec) and stop the server from sending more data. This prevents storing large amounts of data in memory by accident. The downside is that any given pipeTo() call might not finish until there is a consumer consuming all the data. If we were to run the concatenation loop directly in the streamBlob() function, we’d potentially end up in a deadlock scenario: The input stream can’t finish until someone starts consuming the buffered up data. The buffered data can’t be consumed until the ReadableStream has been returned from the function. The function can’t return a value until all input streams have been forwarded. An AIIFE let’s us resolve this circular dependency by running the concatenation loop concurrently.
Something that is easy for forget with AIIFEs is that any thrown error will not bubble up, but instead reject the promise the AIIFE returns. Since no one is actually doing anything with the return value of the AIIFE, that error will either get lost or, like in some runtimes, cause an error log and potentially end the process. There’s many different ways to handle this, and it depends on the context what the right way forward is. Arguably the cleanest version would be to refactor the streamBlob() function to take a WritableStream, letting the caller decide which route to take. But for this experiment, I am just going to attach a catch() handler to the AIIFE and log the error:
const { readable, writable } = new TransformStream();
(async () => {
// ... same as before ..
})().catch((err) => console.error(err));
return new Response(readable);
Videos
This works really well as a way for my frontend to request full files, no matter how large, from the /raw endpoint. However, video files were not quite working as I expected: They played just fine, but I was not able to skip ahead in a video. Digging into the requests sent by the browser, it became clear that the <video> tag uses HTTP Range requests to jump ahead in a video, and my streamBlob() function doesn’t handle range requests at all.
Range requests
Range requests allow you to download a range within a file by specifying a start byte and an end byte via a request header:
fetch("/")
.then((resp) => resp.text())
.then((v) => console.log(v.length));
// Logs 11629 (or something similar)
fetch("/", { headers: { range: "bytes=0-10" } })
.then((resp) => resp.text())
.then((v) => console.log(v.length));
// Logs 11
The Range header in a request specifies the start and the end byte that you want to request. Note that the end byte is optional and inclusive. If omitted, the resources is streamed until the end. The server should respond with a HTTP 206 (“Partial content”) status code and a Content-Range header, specifying the start byte, end byte and total size of the resource. Content-Length should be set to the length of the returned range, not the total size of the resource. Note that the server is allower per spec to change the range that was requested and even ignore the fact that it was a range request, but many browsers don’t support this well and fallback to requesting the full resource without a Range header. If you want more details, take a look at the MDN article. Another thing to watch out for is the fact that many development webservers like superstatic, http-serve or similar do not support range requests. They ignore the Range header and just respond with the full resource. Most production webservers, however, do support range requests for static content out of the box, and that also applies to Deno’s std/http/file_server.
<video> and range requests
Observing what a <video> tag does in Chrome when loading a video file is quite interesting: First the browser issues a GET request to start streaming the video file from the start, using the header Range: bytes=0-. If the server does not support range requests, it will respon with a normal HTTP 200 (“OK”) and the <video> tag will disable skipping while the full file loads.
When developing with a local web server, the video will buffer incredibly quickly. I used DevTool’s network throttling to slow that down and allow me to get ahead of the buffer indicator. However, it turns out that DevTools does not completely faithfully emulate low network conditions: It doesn’t signal the backpressure to the webserver. So while the rendering process only sees data come in at the throttled rate, the server will be allowed to keep sending data at full speed. It seems that some other parts of Chrome are also doing their work before network throttling is applied, because the requested ranges on the server side didn’t quite add up with what I was seeing in the network panel.
To make sure I have consistent behavior — and in the spirit of using streams — I implemented a TransformStream that throttles the delivery of any network data to a rate of my choice. It’s not perfectly exact at enforcing the bandwidth, but it does the job:
function throttle(
targetBytesPerSecond: number
): TransformStream<Uint8Array, Uint8Array> {
return new TransformStream({
async transform(chunk, controller) {
// Send a 1/10th of the data quota every 100ms
while (chunk.byteLength > 0) {
const boundary = Math.floor(targetBytesPerSecond / 10);
controller.enqueue(chunk.subarray(0, boundary));
chunk = chunk.subarray(boundary);
await sleep(100);
}
},
});
}
function handle(request: Request): Promise<Response> {
// ... as before ...
const throttledBody = response.body!.pipeThrough(throttle(54000));
// `response.body` is read-only (i.e. a getter function). Luckily,
// creating an identical response with a new body is well-supported
// by the constructor.
return new Response(throttledBody, response);
}
I also added some detailed logging to my development server to compare which range has been requested and how many bytes have actually been sent. Those two values needn’t be the same as the browser can cancel the transmission of a response early. With all of this in place, I could take a closer look at the <video> tag and its use of range requests.
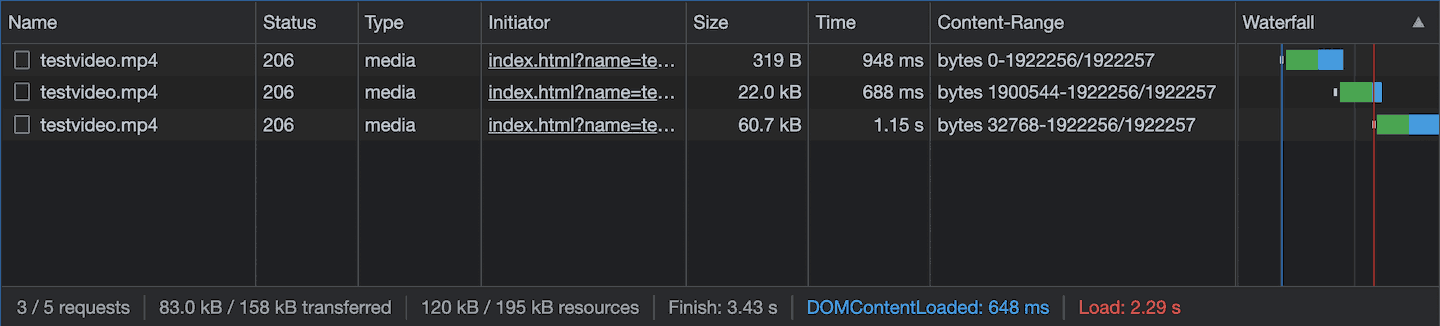
$ deno run --allow-net --allow-read testserver.ts
Done /index.html
Requested: null
Sent: 443
==========================
Cancel (Http: connection closed before message completed) /testvideo.mp4
Requested: bytes=0-
Sent: 38368
==========================
Done /testvideo.mp4
Requested: bytes=1900544-
Sent: 21713
==========================
Cancel (Http: connection closed before message completed) /testvideo.mp4
Requested: bytes=32768-
Sent: 71136
...
If you load an MP4 file, the metadata that allows the browser to map a time code to a byte offset in the file is usually placed at the end of the file. You can see how the browser loads the start of the file (in my experiments it was roughly the first 32K). I assume to look up the start and size of the footer data. It then aborts that request and sends another range request for the footer of the file. Now that the browser knows the dimension, duration and other important data about the video, it can show the player controls and make a new request to buffer up the video data. It’s worth noting that MP4 can actually have the necessary metadata at the start, which will save you a round trip and will make your MP4 play earlier. If you use ffmpeg, you can frontload the metadata by adding the -movflags faststart flag to your invocation.
With WebM, which is a Matroska container with a VP8 video stream, the metadata seems to be placed at the end of the file as well, but for some reason Chrome’s <video> tag only grabs it once you press play, making playback start with a delay.
If you skip ahead in the video (past the buffer indicator), the browser will cancel the currently on-going response for the video content. It will then use the the video file’s metadata to map your desired new position to a byte offset and use it for a new range request. If you pause a video, you can see the video buffer indicator buffer up a certain amount of content, and then stop. This is the backpressure at work! The buffer is full and the browser stops the server from sending more data. The request is technically still on-going, just no data is being sent. If you press play again, the server will resume sending data. However, if you wait too long between pausing and resuming, the request might have been cancelled and a new request will be sent when you press play.
Implementing range requests
Back to our perkeep data structure. While serveFile() does support range requests, our own streamBlob() does not. Each part in the file’s parts list comes with the hash of that chunk as well as that chunk’s size. Supporting range requests on these resources would be somewhat straight forward: Go through the parts list, add up the size properties until we reach the start byte, then send the chunks (cropping them if required) until the end byte is reached. Fin.
But wouldn’t it be fun to rather have a generic TransformStream that extracts a byte range from any ReadableStream<Uint8Array>? It’s less efficient because under the hood we are still streaming the whole response, but right now I care about making it work and having fun, rather than doing it right, let alone fast.
export function slice(
start: number = 0,
end: number = Number.POSITIVE_INFINITY
): TransformStream<Uint8Array, Uint8Array> {
return new TransformStream({
transform(chunk, controller) {
const subchunk = chunk.subarray(
clamp(0, start, chunk.byteLength),
clamp(0, end + 1, chunk.byteLength)
);
start -= chunk.byteLength;
end -= chunk.byteLength;
if(subchunk.byteLength > 0)
controller.enqueue(subchunk);
},
});
}
async function streamBlob(
req: Request,
ref: string,
): Promise<Response> {
// ... as before ...
const size = sum(parts.map(part => part.size));
const requestedRange = parseRequestRange(req);
const rangeStart = requestedRange?.start ?? 0;
const rangeEnd = requestedRange?.end ?? (size - 1);
const headers = { "Content-Length": (rangeEnd + 1) - rangeStart };
if (requestedRange) {
headers["Content-Range"] = `bytes ${rangeStart}-${rangeEnd}/${size}`;
}
return new Response(
readable.pipeThrough(slice(rangeStart, rangeEnd)),
{
status: requestRange ? 206 : 200
headers
}
);
}
Instead of counting the number of bytes we have sent, we move the start and end bytes backwards with every chunk that we forward. We also make use of typedArrayView.subarray(start, end?), which returns a new view onto the underlying buffer; so without having to do any copying. And with this in place, seeking in videos works!
Conclusion
This was just me playing around with the <video> tag and their usage of range requests, which unexpectedly led me down the path of WHATWG streams. Whenever I use them, I can’t help but appreciate how composable their design is. I do think they are one of the most useful things to have in your toolbelt. That’s also what led me to write observables-with-streams, a collection of helper functions for streams.